
Inhaltsverzeichnis
1. Selbstverstärkende Zunahme an Materialnummern
2. Vereinheitlichung bestehender Materialnummern senkt Kosten
3. KI-Tool analysiert und vereinheitlicht Stammdaten
4. Schritt eins: Vertikale Konsolidierung
5. Schritt zwei: Horizontale Vereinheitlichung
6. Vereinheitlichung der Stammdaten erfolgt „beinahe“ vollautomatisch
Über die letzten Jahre und Jahrzehnte ist die Anzahl der Produktvarianten sowie die damit einhergehende Bauteilvielfalt bei produzierenden Unternehmen kontinuierlich angestiegen. Das ist unter anderem auf historisch gewachsene Produktprogramme, Unternehmenszusammenschlüsse sowie zunehmend kürzere Produktlebenszyklen zurückzuführen.
Eine Studie an der RWTH Aachen University ergab, dass die Anzahl der aktiven Materialnummern bei 127 der 135 teilnehmenden produzierenden Unternehmen über die letzten zehn Jahre ständig zugenommen hat und es darüber hinaus erwartet wird, dass diese weiter zunimmt. Insbesondere bei einfachen Bauteilen gilt häufig die Devise: „Neu machen ist deutlich schneller als suchen!“
Selbstverstärkende Zunahme an Materialnummern
Diese selbstverstärkende Zunahme an Materialnummern führt beispielsweise zu einem Verlust von Skaleneffekten in der Beschaffung, zu neuen Lagerplätzen, neuen Arbeitsplänen oder der Anpassung zulassungsrelevanter Dokumentation. Diese Effekte erzeugen einmalige und laufende Kosten entlang der gesamten Wertschöpfungskette, die teils ausschließlich aufgrund einer neuen Materialnummer anfallen (siehe Grafik).
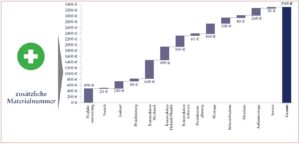
Die Vereinheitlichung der bestehenden Materialnummern, durch das Harmonisieren funktionsgleicher Teile, die mehrmals im System angelegt wurden, bietet erhebliches Potenzial, diese Kosten signifikant zu senken oder gar nicht erst entstehen zu lassen.
Vereinheitlichung bestehender Materialnummern senkt Kosten
Auf die Vereinheitlichung der bestehenden Teilevielfalt wird allerdings häufig aufgrund des enorm hohen Aufwands verzichtet. Darüber hinaus sind die Ressourcen, die für die Vereinheitlichung einzusetzen sind, häufig zu wertvoll für solch monotone und repetitive Tätigkeiten. Für die intelligente Analyse und Verarbeitung großer, heterogener Datenmengen und die automatische Identifikation von Mustern hierin haben sich Verfahren der Künstlichen Intelligenz (KI) bewährt. Die Vereinheitlichung von Stammdaten ist ein idealer Anwendungsfall, um die Potenziale der KI auszuschöpfen und humane Ressourcen erheblich zu entlasten.
KI-Tool analysiert und vereinheitlicht Stammdaten
Am Werkzeugmaschinenlabor WZL der RWTH Aachen University wird daher ein Tool entwickelt, das KI-Methoden verwendet, um bestehende Stammdaten zu analysieren und zu vereinheitlichen. Die Vereinheitlichung erfolgt dabei ausschließlich auf Basis von einfach aus Informationssystemen extrahierbaren Informationen (wie etwa der Bezeichnung oder dem Kurztext), sodass keine aufwendige Anknüpfung an Informationssysteme oder Extraktion von Daten erforderlich sind.
Das entwickelte Tool geht in zwei Schritten vor: der vertikalen Konsolidierung sowie der horizontalen Vereinheitlichung. Diese beiden Schritte sind in der zweiten Grafik anhand beispielhafter Bezeichnungen dargestellt und werden im Folgenden kurz erläutert.
Schritt eins: Vertikale Konsolidierung
Im ersten Schritt, der vertikalen Konsolidierung, findet die Analyse der bestehenden Bauteilvielfalt basierend auf den existierenden Stammdaten statt. Das Ziel ist die Identifikation von Gleichteilen oder ähnlichen Bauteilen basierend auf den zur Verfügung stehenden Informationen. Für die Identifikation von Ähnlichkeiten dienen zwei Hypothesen: 1) „Ähnliches ist ähnlich“ und 2) „Ähnliches geht mit Ähnlichem einher“. In Analogie zu den Sprachwissenschaften werden diese beiden Hypothesen anhand von zwei Ähnlichkeitskriterien quantifiziert, welche als syntaktische und semantische Ähnlichkeiten bezeichnet werden.
- Die syntaktische Ähnlichkeit analysiert die Ähnlichkeit basierend auf den in den Elementen einer Bezeichnung verwendeten Buchstaben und Buchstabenreihenfolgen (zum Beispiel ist Motor ähnlich zu Motro). So lassen sich Abkürzungen und Schreibfehler schnell und automatisch identifizieren und ausgleichen: „Ähnliches ist ähnlich“.
- Die semantische Ähnlichkeit analysiert die Ähnlichkeit basierend auf der Kombinatorik der Elemente einer Bezeichnung. Hierüber lassen sich bei vollständig unterschiedlichen Bezeichnungen (etwa Motor und Antrieb) Ähnlichkeiten identifizieren, wenn diese Worte stets von gleichen oder ähnlichen weiteren Elementen (zum Beispiel kW bzw. Leistung, Volt bzw. Spannung) umringt sind: „Ähnliches geht mit Ähnlichem einher“.
Durch die syntaktische und semantische Ähnlichkeitsanalyse lassen sich sehr schnell gleiche oder sehr ähnliche Teile identifizieren. Die Abhängigkeiten und Ähnlichkeitsmaße der jeweiligen Teile werden im Rahmen des Verfahrens gespeichert, visuell zu Verfügung gestellt und bilden die Grundlage für weitere Analysen. Durch die hierüber erzielte Transparenz kann bereits eine erhebliche Reduzierung der Vielfalt erreicht werden.
Schritt zwei: Horizontale Vereinheitlichung
Im zweiten Schritt, der horizontalen Vereinheitlichung, erfolgt unter Berücksichtigung von zukünftigen Klassifizierungskriterien (etwa nach der Logik von Sachmerkmalleisten) die Vereinheitlichung der Stammdaten in Form von neu generierten Bezeichnungen. In Abbildung 2 folgen diese einer einfachen Logik: eine Teilegruppe (etwa Motor) wird charakterisiert durch dazugehörige Variantentreiber in Form von Merkmalen (etwa Leistung, Spannung oder Umdrehungen) und deren Ausprägungen (etwa Merkmal Leistung, Ausprägungen: 110 kW, 132 kW, 200 kW; Merkmal Spannung, Ausprägungen: 400 V, 1140 V etc.).
Um diese stets einheitlich und in der gleichen Reihenfolge der neuen Bezeichnung zuzuordnen, werden die im ersten Schritt konsolidierten Bezeichnungselemente zunächst mit dem entwickelten und angelernten Algorithmus klassifiziert, wobei jedem Element ein Label zugeordnet wird. So kann beispielsweise automatisch aus den Elementen kW oder V gefolgert werden, dass diese auf die Definition von Leistung oder Spannung hinweisen und somit in der Regel Merkmale für Motoren darstellen.
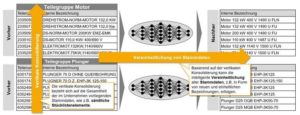
Die identifizierten Label werden weiterhin regelbasiert quantifiziert, das heißt den Merkmalen werden die dazugehörigen Ausprägungen zugeordnet. Eine einfache Regel ist beispielsweise, dass die Quantifizierung (132) vor der dazugehörigen Einheit (kW) steht. Da diese Regeln merkmal- und unternehmensspezifisch variieren, ist eine absolute Definition beinahe unmöglich, weshalb ein neuronales Netz zur situative Differenzierung eingesetzt wird.
Vereinheitlichung der Stammdaten erfolgt „beinahe“ vollautomatisch
Über das „labelling“ und die Zuordnung von Merkmalen zu Teilegruppen sowie von Ausprägungen zu Merkmalen kann insgesamt „beinahe“ vollautomatisch eine Vereinheitlichung der Stammdaten erfolgen. Beinahe deshalb, da bei unzureichender Sicherheit eine Überprüfung durch Experten erforderlich wird, um zukünftig gleiche und ähnliche Situationen besser bewältigen zu können. So wird der Algorithmus unternehmensspezifisch spezialisiert und lernt ständig dazu.
Insgesamt wird über das entwickelte Tool die Vereinheitlichung bestehender Stammdaten unter deutlich geringerem Ressourceneinsatz ermöglicht.
Wir würden uns freuen, das Verfahren mit produzierenden Unternehmen anzuwenden und insgesamt zu einer Steigerung der Ressourceneffizienz und Produktivität beitragen zu können. Die Wissenschaftler des WZL bieten das Verfahren für die Industrie an, um Unternehmen dabei zu unterstützen, ihre Produktivität zu steigern.









{kind=link}